비지도학습 상황에서 자연어 처리를 통한 감정분석
해당 프로젝트는 산업공학과 대학원 수업 “비정형 데이터 분석”의 Final Project로 진행했던 프로젝트입니다.
Motivation

투자에 대한 의사 결정을 내릴 때, 해당 기업이 현재 어떠한 평가를 받고 있는지 파악하는 것은 중요합니다. 워렌 버핏과 같은 사람은 사업보고서를 통해 내가 관심있는 회사가 어떤 사업을 하고 있는지, 보고서에 어떠한 평가가 담겨있는지 손쉽게 파악할 수 있습니다. 하지만 도메인 지식이 없는 일반인들에게 사업보고서는 너무 어렵게 다가오며, 기사를 통해 이를 대신 파악할 수는 있지만 매일 쏟아지는 엄청난 양의 기사를 날마다 읽는 것은 굉장히 힘든 일입니다.
이를 기계가 자동으로 읽어주고 공시일 기준 현재 기업이 받는 평가가 얼마나 긍정적인 평가를 받고 있는지만 수치로 투자자에게 전달해준다면, 투자자 입장에서는 많은 시간과 노력을 아끼며 의사결정에 많은 도움을 받을 수 있다고 생각하였습니다.
Framework

Data Extraction
가장 처음으로는 기업을 선정하였습니다. 분기마다 사업보고서를 공시하는 기업이어야 하며 특정 이슈가 발생한다면 이것이 기사화 될 정도의 기업이어야 했습니다. 또한, 업력이 오래된 기업을 선정하였습니다.
- KOSPI 200
- 10년 이상 상장
- 상위 25개 기업
데이터는 크게 두 가지를 활용하였습니다.
1.사업보고서
기업의 사업보고서는 DART 페이지에서 크롤링했습니다. 분기와 반기 보고서 모두 수집하였고 약 1,000여개의 보고서가 수집되었습니다.
2.신문기사
신문기사는 2008년 ~ 2017년 사이에 매일경제와 한국경제의 기사들을 모두 크롤링하였습니다. 이 과정에서 약 55,000여개의 기사가 수집되었습니다.
Data Preprocessing
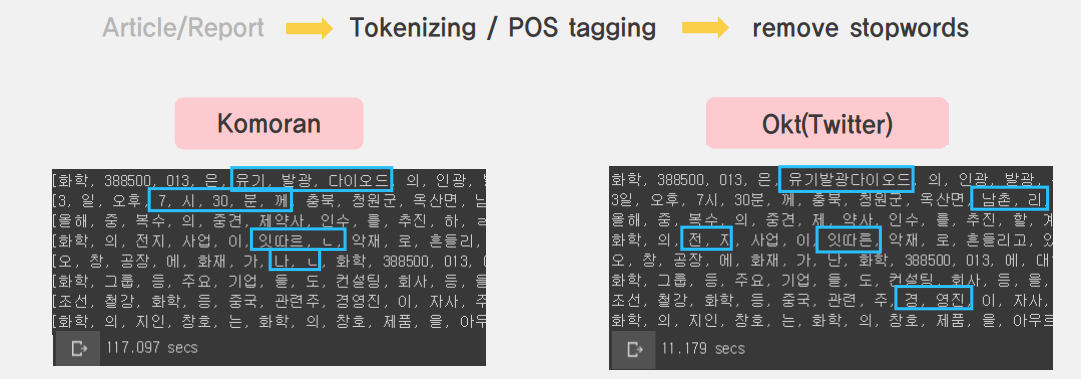
데이터 전처리는 수집된 원문을 Tokenizer를 거쳐 쪼개준 후 POS tagging을 진행해주었습니다. 이 과정에서 여러개의 tokenizer들에 대한 성능비교를 진행했었는데, 대표적으로 Komoram과 Okt 두 개의 실험 결과를 실어보았습니다.
Komoran은 Okt 대비 세분화된 결과를 제공합니다. 그러나 추후 저희가 주로 이용할 POS 중 하나인 명사에서는 큰 차이가 없는 것으로 판단했습니다. 또한, 동일한 240개 data에 대한 형태소 분석 시간을 비교해보았을 때, Komoran이 10배 정도 더 많은 시간이 소요되었습니다. 이러한 점을 복합적으로 고려하여 최종적으로 Okt 현태소 분석기를 이용하였습니다. (cf: 해당 결과는 2019년도 상반기에 진행된 실험입니다. 현재는 kakao에서 발표한 형태소 분석기 등 더 다양하고 성능이 개선된 분석기들이 많아졌기 때문에 기존에 진행된 프로젝트의 소개로만 봐주시면 감사하겠습니다.)
Pos tagging을 진행한 후에는 형태소 분석이 제한되며 감정분석에 큰 의미부여가 되지 않는 불용어를 제거해주었습니다.

Modeling
Summary
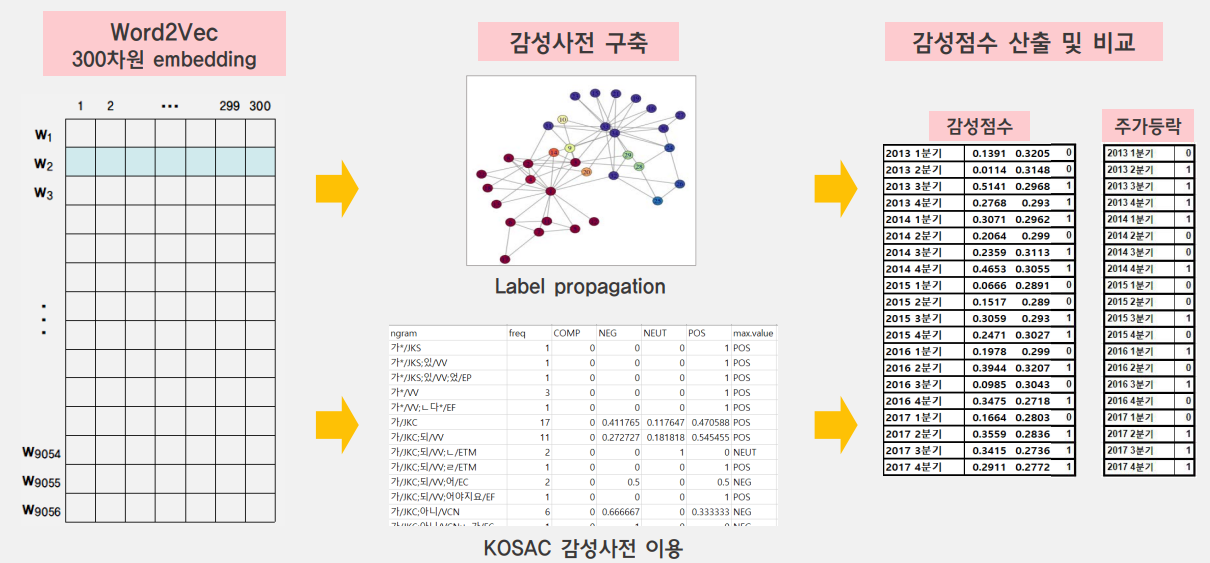
임베딩 과정을 거치고 난 후 이번 프로젝트의 가장 핵심이었던 부분은 지도학습의 영역이었던 감정분석을 비지도학습 상황에서 해결해야 했던 것 이었습니다. 이를 위해서 일부 기준 단어를 선정하고 이 단어에 사람이 label을 부여한 후 Label Propagation을 이용하여 각 단어에 label을 부여하는 준지도 학습 방법으로 바꾸어서 문제를 해결하였습니다.
Label Propagation
이 방법은 network graph 방법론 중 하나로서, 단어 하나를 하나의 노드로 놓고 다른 노드들 사이의 거리를 재서 가까운 노드의 label을 전파하는 방식입니다. 이렇게 가까운 노드들을 연결하는 방법도 여러가지가 있지만 그 중에서 특정 거리인 epsilon 보다 가까운 노드만 연결하는 Epsilon-neighborhood graph 방법을 가장 먼저 고려하였습니다.
이렇게 전파된 label들 중 이미 사람이 정답 label 300개를 test set으로 지정하였고 정확도는 약 33% 수준이었습니다. 감정분석의 핵심은 얼마나 정확도 높은 감성사전을 구축하느냐 입니다. 따라서 프로젝트 수행의 대부분의 시간을 이 정확도를 높이는 데 초점을 두었습니다. 1차적으로 정확도를 높이기 위하여 다음과 같은 처치를 진행하였습니다.
- Epsilon-neighborhood graph -> Fully-connected graph
- RBF kernel을 이용하여 거리가 가까운 노드에 가중치 부여
- Word2Vec tuning
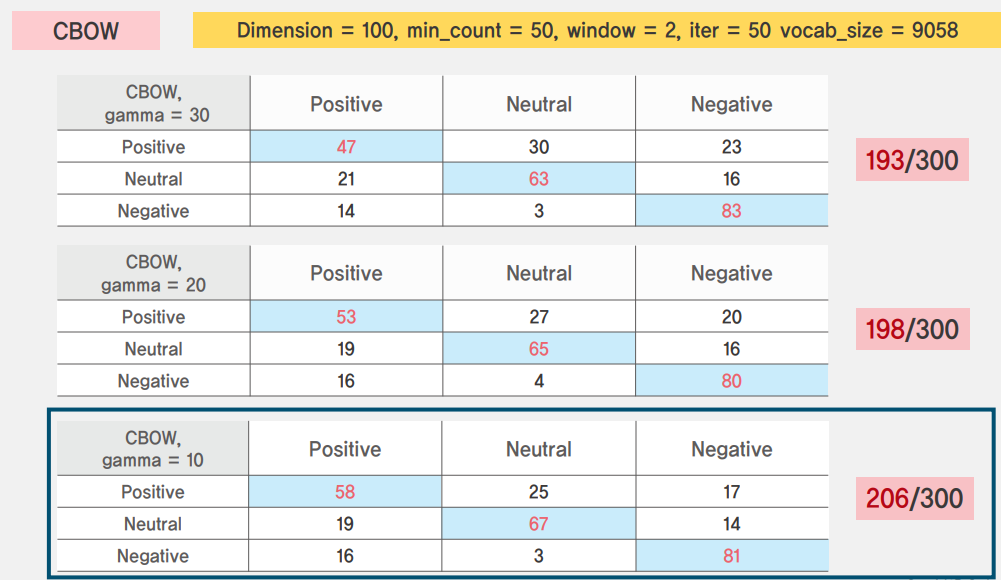
결과 사진에는 넣지 않았지만 skip-gram과의 비교먼저 진행하였지만 거의 모든 상황에서 CBOW를 이용했을 때의 성능이 더 좋았습니다. 결과적으로는 정확도를 약 69%까지 상승시켰습니다.
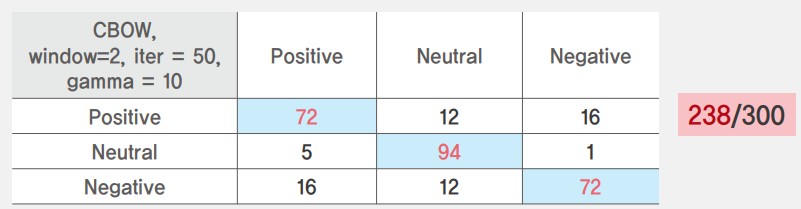
다음으로 감성사전의 정확도를 높이기 위한 시도는 사람이 label을 선정하는 기준 단어 선정을 빈도수에서 단어의 중심성으로 바꾸었습니다. 단어의 중심성이 높은 단어란 임베딩 후 RBF kernel 기반으로 거리 가중치를 부여하였을 때, 가장 높은 가중치 합을 보유한 단어를 의미합니다. 즉, 짧은 거리의 연결선이 많을수록 중심단어가 된다는 뜻입니다. 각 단어의 중심성을 구하고 높은 중심성을 갖는 단어들을 기준 단어로 선정하여 직접 label을 부여하였고 이 방법으로 정확도를 약 80%까지 끌어올렸습니다.
Analysis
이렇게 구축된 사전을 바탕으로 test 기업으로 선정한 기업들의 공시일 전 10개 기사의 Sentiment Score를 산출하였습니다. 이렇게 산출된 신문기사의 감성 점수와 사업보고서의 감성점수를 합산하여 최종 감성 점수를 산출하였습니다.
Sentiment Score = (# of Positive - # of Negaive) / (# of Positive + # of Negative)
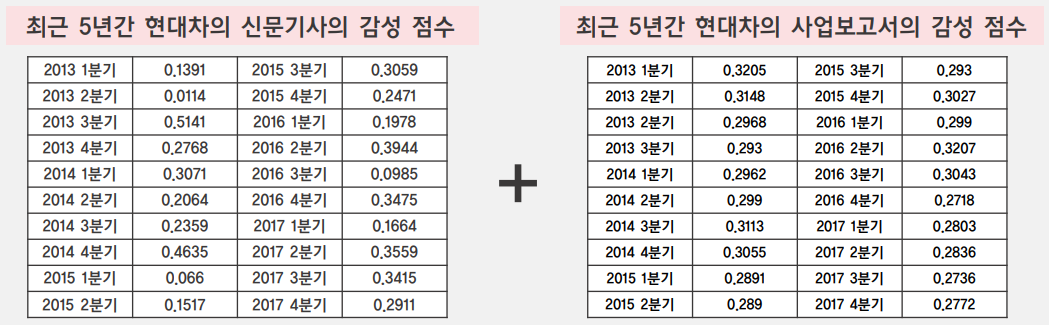
이 때, 신문기사와 사업보고서의 점수를 합산하는데 약간의 문제가 있었습니다. 위의 결과를 보면 신문기사의 감성 점수는 분산이 큰데 비해 사업보고서의 감성 점수는 분산이 굉장히 작았습니다. 이는 부정적인 뉘앙스의 어휘 사용이 지양되는 사업보고서의 특성이라고 생각되었고, 최종 감성 점수의 편차를 위해서는 사업보고서 보다(0.3) 신문기사에 더 많은 가중치(0.7)를 주어 최종 감성 점수를 산출하였습니다. 그리고 산출된 감성 점수는 0.5를 기준으로 긍정이면 1, 부정이면 0으로 최종 labeling을 진행하였습니다.
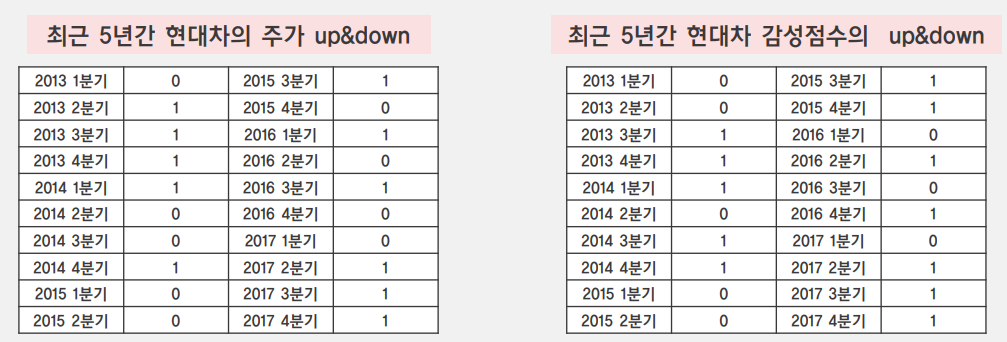
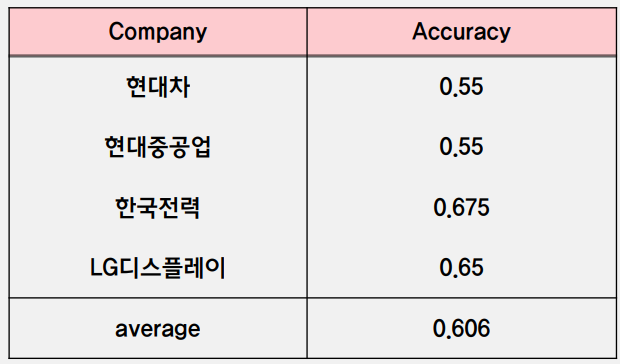
이러한 방식으로 test 기업으로 선정한 4개 기업에 대한 up&down의 정확도를 측정하였고 4개 기업에 대한 정확도 평균은 0.606이 나왔습니다. SNU data minimg center에서 2017년 word embedding 비교를 위해 감성 사전을 구축하고 기업의 주가 등락 방향성을 예측한 논문에서 약 0.62정도의 정확도를 달성한 것을 고려해보면 크게 나쁘지 않은 성능이라는 것을 알 수 있습니다.
Limitation
위와 같은 전통적인 NLP에서는 형태소 분석기의 성능이 무엇보다 중요합니다. 하지만 당시 프로젝트를 진행했을 때 이용했던 형태소 분석기는 지금과 비교하면 상당히 떨어지는 성능을 갖고 있습니다. 더 좋은 형태소 분석기를 사용한다면 더 높은 결과를 기대할 수 있습니다.
또한, 당시에는 임베딩 방법에 Word2Vec만을 이용하였는데, FastText와 sentiment analysis에 특화된 더 성능이 좋은 임베딩 방법이 많이 소개되었습니다. 이 또한, 성능 향상을 기대할 수 있는 요인 중 하나라고 생각합니다.
마지막으로는 Analysis 부분의 논리와 섬세함이 부족했다고 생각합니다. 당시를 회상해보면 Modeling 과정까지에 너무 많은 시간을 할애하였던 것 같습니다. 주가 예측이라는 주제는 경제 분야의 연구 활동에서는 꽤나 빈번하게 다루어지는 주제이기 떄문에 해당 연구들을 조사하면 더 합리적인 마무리가 될 수 있을 것이라 생각합니다.
회고
해당 프로젝트는 저 포함 3명이 함께 진행한 프로젝트였습니다. 당시 저희 조원들은 비정형데이터 분석에 대해서는 모두 거의 문외한이라고 부를 수 있을 정도의 수준이었습니다. 당시 8개 정도의 조가 있었는데 제안 발표 때의 평가는 저희 조가 꼴등인가 꼴등에서 두 번째였던 것으로 기억합니다. 하지만 마지막 최종 발표 당시에는 순위가 공개되지는 않았지만 마지막 analysis 부분을 조금 더 다듬어서 논문으로 작성해보는 것도 좋겠다는 담당 교수님의 피드백도 있었는데 해당 피드백은 저희 조에게만 주셨습니다. 지금 생각해보면 연구적으로 굉장한 성취를 달성했다기보다는 논문으로 출고하기에 적합한 주제와 흐름인 것이 더 큰 이유였던 것 같지만 당시에는 굉장히 큰 만족감을 느꼈습니다. 다양한 논문을 읽고 아이디어를 얻어 이를 실제로 구현해나가는 것이 굉장히 고통스러운 작업이었지만, 거짓말처럼 정확도가 상승하는 것을 볼때마다 굉장히 큰 성취감을 느꼈었습니다. 당시 연이어서 “와, 이게 되네!” 를 외쳤던 기억이 납니다. 지금은 어떤 문제를 해결하기 위해서 방법론을 찾고 논문에서 아이디어를 얻고 이를 구현하고 실제 문제를 해결하는 것이 꽤나 자연스러워졌는데, 지금 생각해보면 이 프로젝트가 그 출발이었던 것이 아닌가 싶습니다. 어디에다 내놓기 부끄러운 수준의 프로젝트지만 저에게는 꽤나 큰 의미를 갖고 있는, 연구가 무엇인지 처음 경험해본 프로젝트라고 생각합니다.