MLOps를 통한 Auto-Feature Selection
why?
저희 팀에서 모델링을 통해 해결해야 하는 문제들은 다음과 같았습니다.
- 복귀 확률 예측을 통한 복귀 이용자 탐색
- 과금 확률 예측을 통한 과금 이용자 탐색
- 광고에 잘 반응하는 광고 반응성 모델 개발
- 특정 집단과 유사한 유저들을 찾아주는 유사 타겟 모델 개발
하지만 이러한 문제에 접근하기 위해 넥슨 내부에서 주로 이용하고 있는 데이터는 접속, 과금과 같은 서비스 이용에서 파생되는 일부 데이터였습니다. 이용자의 개인정보를 이용하기는 어렵기 때문에 한정적인 데이터를 활용할 수 밖에 없었고,이와는 별개로 캐릭터가 서비스를 이용하면서 만들어지는 로그 데이터가 존재하였지만 워낙 방대하였기 때문에 이용이 어려운 상황이었습니다.
예를 들어서 특정 서비스에서 유저가 강화한 아이템 정보를 모두 수집하고 있었는데, 특정 아이템이 파괴 된다면 자연스럽게 이탈로 이어지거나 강화에 성공한다면 높은 확률로 과금으로 이어지는 아이템들이 존재합니다. 하지만 아이템의 종류만해도 수 천가지가 넘고 이를 하나하나 DB에서 꺼내와서 가공하고 모델에 넣고 결과를 확인하는 것은 거의 불가능에 가깝습니다.
이러한 이슈로 인해 보석과도 같은 데이터들이 쉽사리 이용되지 못하고 있었고, MLOps를 통해 모델링을 자동화하고 결과를 저장하여 모니터링 한다면 더 손쉽게 문제 해결이 가능할 것이라는 생각으로 시작된 프로젝트였습니다.
HOW?
Process Summary
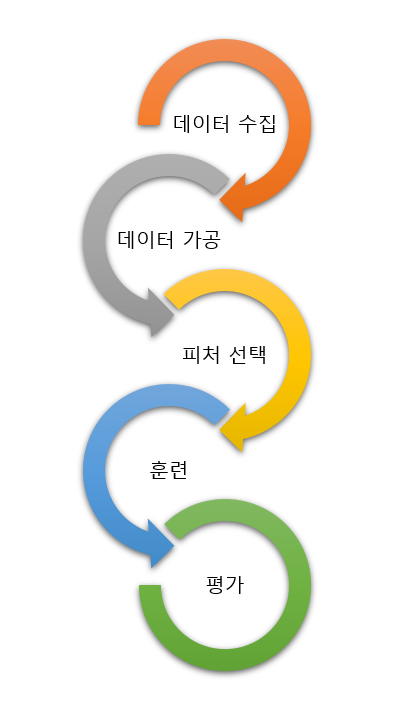
1. 데이터 수집
개발 이후 로그 형태로 쌓여있던 데이터를 일별 배치를 이용해서 특정 서비스의 로그를 아래와 같은 형태의 테이블을 DB에 적재하기 시작하였습니다. 해당 부분은 DB에 관한 개발이 필요했던 관계로 개발자셨던 팀장님께서 설계를 진행해주셨고, 같은 팀 개발자 분께서 구현해주셨습니다.

이 과정에서 제가 진행한 부분은 필요한 피처들을 선별하고 식별자에 대한 기준을 정하고 적재에 필요한 로그 가공 형태를 지정하는 것 이었습니다.
2. 데이터 가공
MLOps를 위한 가장 첫 부분은 적재된 DB에서 데이터를 불러오는 것 이었습니다. 제플린 환경에서 pyspark 문법을 이용하여 서비스, 날짜, 훈련에 이용하고 싶은 피처 id를 입력하면 하나의 유저 구분 식별자에 그에 따른 피처가 붙도록 테이블을 생성하였습니다.
raw 데이터에는 하나의 유저 식별자가 여러 row 존재하고 있습니다. 하지만 대부분의 문제 상황이 특정 유저에 대한 복귀, 과금, 클릭과 같은 것들의 예측이기 때문에 훈련에는 하나의 row에 하나의 유저 식별자가 들어가야 했습니다. 이 때문에 테이블을 pivot한 형태로 변경하였고, 아래 결과 테이블과 같이 굉장히 sparse한 테이블이 생성되게 되었습니다.
예를 들어서 특정 스킬을 사용하여 보스 몬스터를 처치한 경우 수 많은 스킬 중에 하나의 스킬만을 사용하였다면 그 스킬만 count되고 나머지 수 백, 수 천개의 피처는 0이 되기 때문입니다. 이는 추후 모델링을 하는 과정에서 모델을 선택하는데 중요한 요인으로 작용하였습니다.
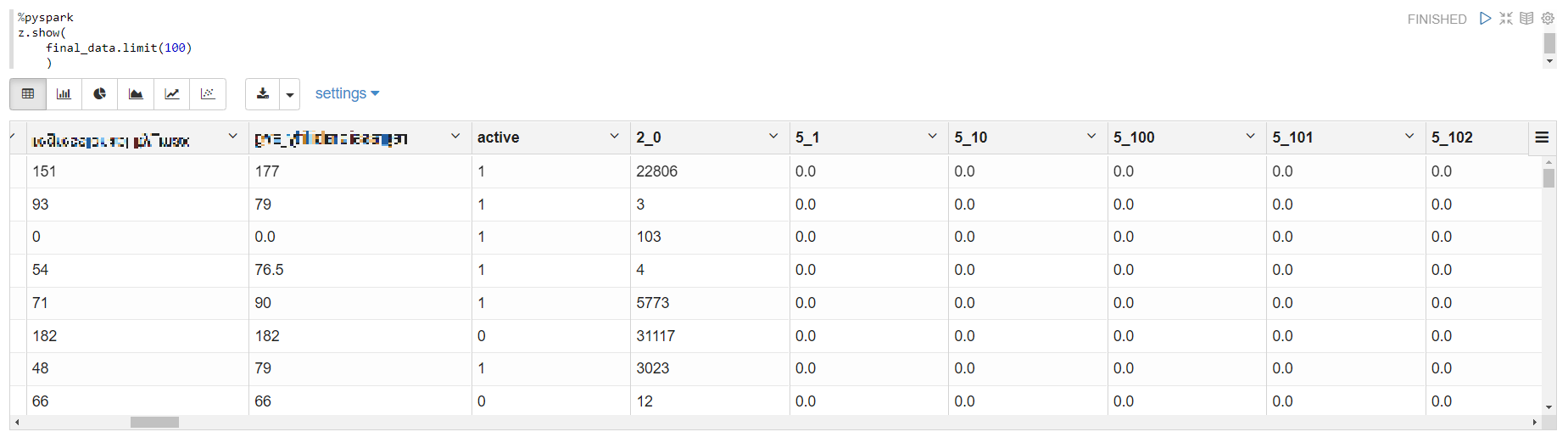
이렇게 만들어진 테이블은 저희 팀의 특정 s3 버킷으로 생성되게 코드를 작성하였습니다. 해당 코드는 모두 하나의 제플린 노트북에 작성하였습니다. 해당 노트북을 하나의 DAG로 하여 매일 오전 10시에 배치가 동작하도록 프로그램을 활용하여 프로세스를 만들었습니다. 다행히도 회사 차원에서 개발자 외의 직군들도 배치 프로세스를 쉽게 이용할 수 있게 만든 프로그램이 있었고, 이를 이용하여 직접 서버에서 ETL 코드를 작성하지 않아도 자동으로 배치를 실행시킬 수 있었습니다.
3. 피처 선택
Data load
보통 모델링은 s3 서버 자원을 활용하여 진행하지만, 현재까지 진행된 프로젝트는 프로토 타입으로 진행이 되고 있었기 때문에 우선 로컬에서 모델링을 진행하기로 하였습니다. 빠른 결과 시각화를 위해 주피터 환경을 이용하기로 하였습니다. MLOps를 위해서는 모든 과정에 대한 자동화 프로세스를 구축하는 것이 최우선 과제였습니다. 하지만 로컬에서는 특별히 일 배치처럼 주기적으로, 혹은 특정 조건을 만족하면 노트북을 자동으로 실행시킬 방법이 없었기 때문에 이를 해결할 방법이 필요했습니다.
방법을 찾던 중 s3에 파일 업로드가 완료되면 _SUCCESS 파일이 항상 생성된다는 것을 알게 되었고, 이를 트리거로 하여 s3의 특정 경로에 해당 파일이 생성된다면 모델링을 실행할 수 있게 만들 수 있지 않을까 하는 생각이 들었습니다.
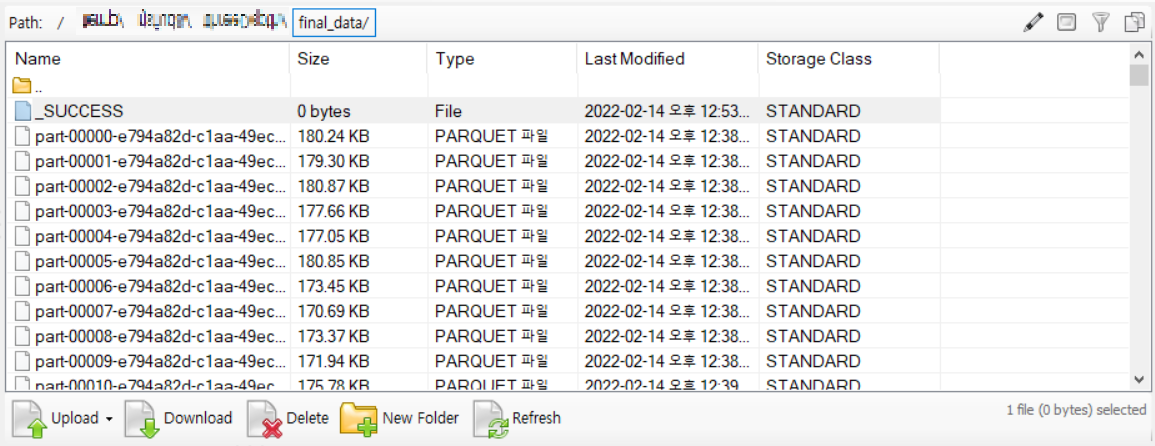
이를 위해서 s3를 로컬 환경에서 접근할 수 있도록 권한을 부여하여 테이블이 생성되는 버킷의 경로에 접근하였고, 무한 반복문을 이용하여 해당 경로에 _SUCCESS란 이름의 파일이 생성되면 그 아래 parquet 파일을 모두 읽어오게 코드를 작성하였습니다. 또한, 특정 데이터 프레임이 생성되면 이를 이용하여 전반적인 모델링이 진행되게끔 트리거를 심었습니다.
Training
앞으로 진행될 데이터 전처리와 훈련은 성능의 향상보다는 수행 시간에 초점을 두어 최대한 간단하게 프로세스가 진행될 수 있는 방법들을 선택하였습니다. 데이터 전처리는 min max scaling을 적용하여 모델 적합이 효율적으로 진행하도록 transform을 진행하였고 높은 상관관계를 갖는 피처를 제거하였습니다. 또한, 이번 프로젝트의 프로토타입을 위한 문제는 앞서 진행했던 복귀 확률 예측으로 하였습니다.(참고 링크: https://gunlyungyou.github.io/classification/first/)
다만 데이터 가공 단계에서도 언급했던대로, 데이터의 sparsness 문제를 무시할 수 없었습니다. Rong Gong(2017) 등을 보면 VGG나 Restnet 등 주로 이미지 처리에서 발전하였던 신경망 구조들이 높은 차원의 데이터에서는 여타 부스팅 기반의 알고리즘 보다 더 높은 정확도를 보여준다는 것을 확인했습니다. 이를 기반으로 프로토타입 모델은 경량화 된 Resnet 단일 모델을 이용하였습니다. hyperparameter 조정은 learning rate와 optimizer 일부만을 grid search를 이용하여 진행하였습니다.
Validation
평가 지표는 앞선 복귀 모델과 동일하게 AUC와 Recall(복귀라고 예측한 것 중 실제 복귀)을 주로 확인하였고 AUC 기준 0.67 정도의 성능이 나왔습니다. 이번 프로토 타입의 목적은 성능보다는 전 과정의 자동화에 초점이 맞추어져 있었기 때문에 더 이상의 성능 향상에 리소스를 투입하지 않았습니다.
사용한 모델은 신경망 종류였기 때문에 기존에 트리 계열의 앙상블 모형이나 부스팅 모형에서 많이 사용하던 feature importance라고 불리는 것들을 이용하지 못하였습니다. 대신 SM Lundberg(2017)에 소개되어서 최근 많이 사용되고 있는 SHAP value를 feature importance로 이용하였습니다.
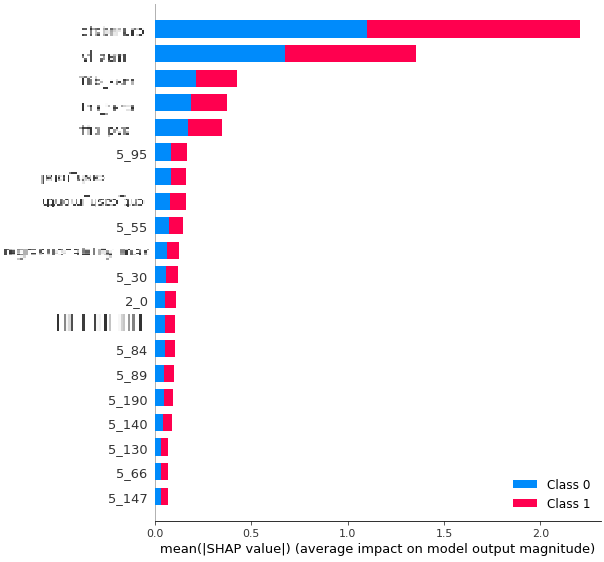
결과를 보면 상위에 위치하고 있는 피처들은 모두 KPI 피처들(블러처리된 부분)이고 새롭게 추가된 인게임 로그 피처들은 영향도가 상당히 낮은 것으로 확인되고 있습니다. 해당 결과는 모델링이 끝나면 자동으로 s3에 아래와 같이 저장되고 있으며, 결과가 저장되면 이용된 데이터는 삭제되어 데이터가 다시 s3에 생성되기 전까지는 모델링 작업이 멈추게 됩니다.
현재 주기적으로 로그들이 정제되어 DB에 쌓이고 있으며 니즈가 있을때마다 결과 파일만 확인하고 있습니다.
4. 개선 방향
-
가장 우선적으로 개선되어야 할 부분은 항상 주피터를 실행시켜놔야 한다는 것 입니다. 이를 서버로 옮기고 주기적으로 서버를 구동시켜 모델링 코드 부분이 실행되게 바꿀 예정입니다.
-
데이터 가공 부분에서 원하는 서비스, 날짜, 피처를 조정하는 부분을 위해 개발 리소스가 투입될 예정입니다. 이는 팀 내에서 내부 시스템 개발을 담당해주시는 분께서 도움을 주실 예정입니다.
-
복귀 확률 예측 이외에 모든 문제에도 적용할 수 있게 일반화할 계획입니다.