Vision Transformer를 이용한 실시간 고객 이탈 예측 모델(On-Going)
why?
1.Sequence 데이터 이용의 필요성
기존에 저희 조직에서 주로 개발되었던 이탈 모델은 특정 기간 동안 유저들의 접속, 과금, 플레이 패턴 등의 정보를 요약해서 피쳐로 이용하였습니다. 예를 들어서 3개월 동안 어떤 유저의 총 접속 횟수나 평균 플레이타임 등의 정보를 이용해서 해당 유저가 이탈할지 예측하는 모델을 주로 만들었습니다.
하지만 서비스 이탈위험이 있는 유저는 보통 이탈에 가까운 시점에 접속 주기가 점점 길어진다던지, 과금을 점점 줄인다던지, 일일 퀘스트를 완료하지 않는다던지 등의 신호를 보냅니다. 이 때, 특정 기간 동안의 요약 정보를 이용하면 이러한 신호를 잡아낼 수가 없습니다. 그렇기 때문에 요약 정보 대신 아래의 그림처럼 특정 기간동안의 유저의 정보를 전부 모델에 입력하면 유저가 보내는 이탈 신호를 감지할 수 있게 되고, 이런 신호를 보내는 유저들에게 적절한 마케팅을 한다면 그렇지 않은 유저에 비해 더 긴 리텐션을 확보할 수 있습니다.

2.실시간, 개인화 이탈 예측 모델의 필요성
기존의 모델은 특정 유저의 이탈 확률만을 예측할 뿐 이 유저가 “언제” 이탈할지에 대한 정보는 제공해주지 않고 있습니다. 또한, ML모델의 feautre importance를 통해 이탈에 대한 원인을 추정해볼 수는 있지만 적절한 시기에 적절한 원인을 감지해내기는 어렵습니다.
이러한 한계를 극복하기 위해 특정 기간의 유저 정보를 이미지처럼 활용하여 아래처럼 Attention Mechanism을 적용하면 유저가 언제, 어떠한 이유로 이탈하는 지 감지하여 적절한 시기에 적절한 마케팅을 실시할 수 있게 됩니다.
Attention Mechanism을 이용하면 이미지에서 모델이 어떤 부분을 보고 Y label이라고 예측했는지에 대한 정보를 알 수 있습니다. 이를 x축은 시간, y축은 feauture인 Sequence 이미지에 적용하면 언제, 어떤 이유로 유저가 이탈할 것인지에 대한 힌트를 얻을 수 있습니다.
How?
Data Preprocesing
1.서비스 선정
실시간, 개인화 이탈 모델을 만들고 유저들의 리텐션을 늘리기 위한 마케팅을 진행하기 위해서는, 서비스 외부적인 요소보다는 인게임 요소로 인한 이탈이 많은 서비스가 적당하다고 생각했습니다. 따라서 한판, 한판 단발성의 플레이 패턴을 보이는 서비스보다는 RPG 서비스처럼 복귀나 신규 가입을 했을 때 긴 호흡을 갖고 플레이하는 서비스가 적합하였고, 현재 유저 이탈이 전년 대비 가속화되고 있는 서비스를 선택하여 이에 대한 부양책으로 마케팅을 직접 진행하는 것이 더 많은 필요를 느낄 것이라고 생각하여 현재 넥슨에서 서비스하고 있는 RPG 서비스 중 하나를 선택하였습니다.
2.Label 설정
Y label의 설정은 과제의 난이도를 결정짓고 해당 모델이 얼마나 현실에서 쓰임새가 있는지 결정하게 되는 중요한 부분입니다. 따라서, 최대한 실제 사업부에서 납득하고 바로 마케팅에 이용할 수 있을만한 기준으로 만들었습니다.
- 이탈: 서비스에 연속으로 미접속한 기간이 9일 이상, 17일 미만인 경우
- 잔존: 서비스에 연속으로 미접속한 기간이 9일 미만인 경우
저희 팀 내부에서는 특정 서비스 연속 미접속 기간이 9일 이상인 유저들을 이탈 유저로 정의하고 있습니다. 이는 복귀나 신규 가입한 유저들의 95%가 9일동안 미접속하면 다시 서비스에 돌아오지 않고 장기 이탈로 이어지기 떄문입니다. 또한, 현재 게임을 즐기고 있는 유저인 액티브 유저들은 연속 미접속 기간이 9일 이내이기 때문에 해당 유저들이 일주일 이내에 이탈할 것을 예측하기 위해서는 연속 미접속 기간이 17일 미만인 경우로 설정하였습니다.
예를 들면 데이터 추츨 시점에 어떤 유저가 연속 미접속 기간이 4일인 경우 이 유저는 정의상 아직 액티브 유저이지만 일주일 후에 연속 미접속 기간이 11일이면 이 유저는 데이터 추출 시점에 이탈 유저인 것으로 모델에게 입력되게 됩니다.
3.데이터 준비
데이터는 추출 시점에 액티브 유저 즉, 연속 미접속 기간이 9일 이하인 모든 유저들을 대상으로 하였습니다. 해당 유저들을 바탕으로 일주일 이내에 서비스를 이탈할 것 같은 유저들을 예측하는 것이 목표입니다. 이탈을 예측에 사용할 피쳐는 다음과 같습니다.
- 접속 시간, 접속 횟수, 접속 주기 등 플레이 패턴과 관련된 변수 5종
- 아이템 강화, 몬스터 사냥, 외형 아이템 변경 등의 인게임 요소 2종
데이터는 약 110일 동안의 일별 접속과 로그 정보를 Sequence 이미지로 표현하였습니다. 따라서, 한 유저당 110*7 사이즈의 행렬이 생성이 되며 이를 channel이 1인 이미지처럼 활용하였습니다. 이용한 데이터는 수만 건으로 이 중에서 20%를 testset으로 이용하였습니다.
Modeling
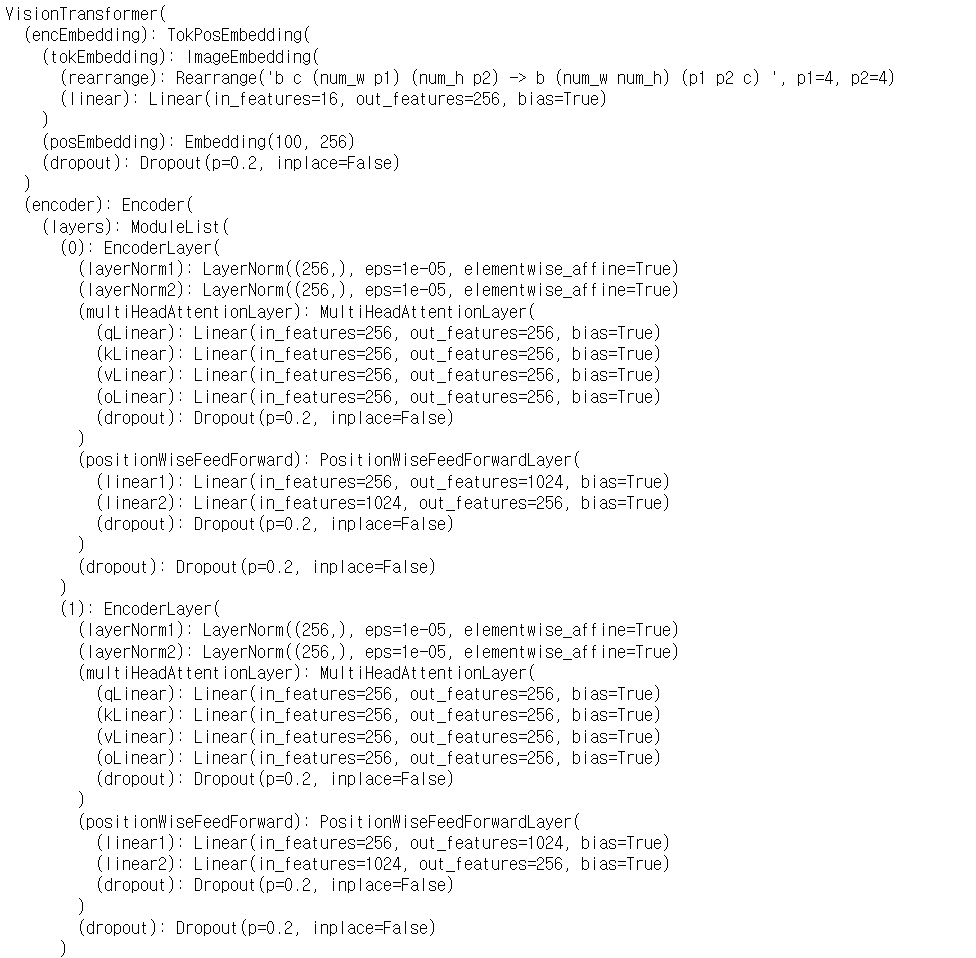
모델은 num_heads = 4, num_layers = 6인 Vision Transformer를 이용하였습니다. 훈련을 위해서 Kubeflow 환경의 노트북을 이용했으며, 성능을 위해 batch_size, learning_rate, class_weight 등의 파라미터를 조정하였습니다. validation은 매 epoch마다 trainset의 약 30%를 이용하여 진행하였습니다. 아래의 사진을 보면 모델의 가장 끝부분이 nn.Linear로 끝나있는 것을 볼 수 있는데, BCELoss 이용을 위해 출력값에 sigmoid를 추가해주었습니다.
모델 layer 정보


Result
1.Test 성능
잔존 유저에 대한 정확도보다 이탈 유저에 대한 정확도가 높은 것이 더 중요하기에 이탈에 더 많은 가중치를 주어 훈련을 진행하였습니다. 아래는 해당 모델링의 Test set 성능입니다.
- Accuracy: 0.977
- F1 score: 0.926
- Recall: 0.995
- Precision: 0.865
모델을 더 깊게 만들고 더 오래 훈련하면 F1 score를 더 높일 가능성이 있습니다.
2.결과 시각화
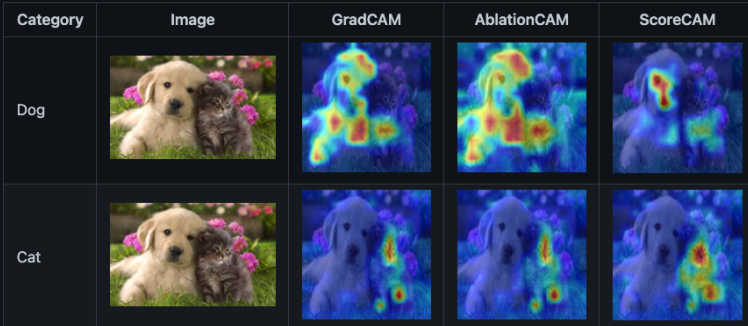
아래의 그림은 모델이 예측했을 때, 어떤 부분을 보고 그렇게 예측했는지 표현한 그림입니다. 왼쪽 그림은 sequence data를 이미지로 표현한 그림이고, 오른쪽 그림은 모델이 어떤 부분을 중점적으로 보았는지 표현한 그림입니다.
(잔존 유저)

왼쪽 그림을 보면 관측한 시간대에서 고루고루 플레이 이력이 있는 유저임을 확인할 수 있습니다. 해당 유저를 보았을 때, 모델은 가운데 부분의 접속 패턴에 초점을 두어 이 유저가 잔존할 것이라고 판단했습니다. 또한, 그 중에서도 두 번째와 여섯 번째 피쳐가 모델이 이러한 판단을 하는데 많은 영향을 주었는데, 해당 피쳐들은 각각 특정 장소에서의 접속 이력과 몬스터 사냥과 관련된 피쳐 중 하나였습니다. 이탈 위험이 있는 유저들 뿐만 아니라 해당 유저들에게도 피쳐와 관련된 마케팅을 집행하면 리텐션을 늘릴 수 있다고 예상됩니다.
(이탈 유저)

왼쪽 그림을 보면 데이터를 관측한 초반 시간대에 활발히 활동했으며 기록이 끊기기 전인 이탈 직전에 특히 활발하게 활동했던 유저인 것을 알 수 있습니다. 오른쪽 그림을 보면 모델은 해당 유저를 이탈할 것이라고 예측했을 때, 초반부의 정보를 중점적으로 참고했음을 알 수 있습니다. 또한, 세 번째와 다섯 번째 피쳐를 중요하게 보고 있는데, 해당 피쳐들은 모두 특정 장소에서의 접속 이력과 관련된 피쳐로 상관관계가 상당히 높은 피쳐로 해석됩니다. 이러한 유저들을 해당 모델을 사용하여 조기에 발견하는 것이 가능하다면, 적절한 처치를 주어 잔존 기간을 더 늘리는 것이 가능할 것이라 예상됩니다.
On-Going
해당 결과를 바탕으로 바로 마케팅을 집행하기는 어렵다고 생각했습니다. 하지만 아이디어를 프로토 타입으로 구현한 결과 상당한 가능성이 있다고 판단하고 있습니다.
그 이유는 우선 만족스러운 성능입니다. 온라인 게임 서비스 churn predicion의 논문들을 살펴보면 대부분의 논문이 0.9 초반대의 성능을 확보하고 있습니다. 이번에 구현한 결과도 이에 부합하는 성능이며, 피쳐를 추가한다면 더 높은 성능을 달성할 수 있습니다. 현재는 마케팅 활동에 도움이 될만한 인게임 피쳐 100여종을 모델에 투입하면서 성능을 확인하고 있습니다.
반대로 해결해야 할 문제도 남아있습니다. 위의 예시처럼 현실적으로 충분한 설명력을 갖고 있는 서로 다른 피쳐들이 높은 상관관계를 갖고 있는 경우 어떤 피쳐를 모델에 이력하여야 하는지, 혹은, 현재는 특정 기간 동안의 유저들의 활동 이력을 살펴보았기 때문에 이미 이탈한 유저의 경우 뒷부분이 padding 처리가 되어 있는데, 이를 가변적으로 가져가야 하는지 등등 방법론을 가다듬고 있습니다.
*추가: 리서치를 하다 TabTransformer: Tabular Data Modeling Using Contextual Embeddings 라는 논문을 발견했는데, 해당 논문도 참고하여 반영할 부분이 있는지 확인이 필요