이탈 유저들에 대한 서비스 복귀 예측 모델링
Concept Summary
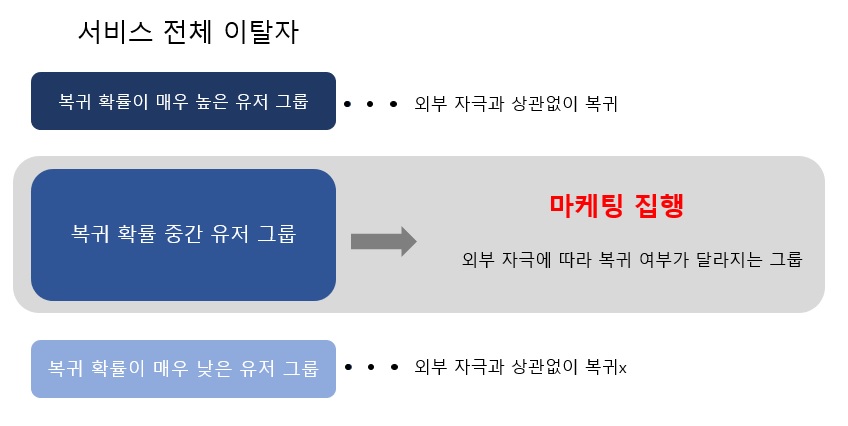
기존에 서비스 이탈자 전체에게 마케팅을 진행하는 것보다 더 효율적인 마케팅을 진행하기 위해 전체 이탈자 중에서 마케팅 여부에 관계없이 복귀할 유저(always-taker)와 복귀를 하지 않을 유저(nerver-takers)를 선별하여 제외한다면 적은 비용으로 동일한 효과를 얻을 수 있지 않을까? 라는 아이디어를 바탕으로 해당 프로젝트를 시작하게 되었습니다.
이를 위해서는 각 서비스 이탈자들의 복귀 확률을 계산해야 했으며, 복귀/미복귀를 label로 한 binary classification 문제로 접근하기로 결정하였습니다.
대상 서비스는 당시 마케팅 예정에 있던 RPG 서비스 중 하나를 선택하였으며 마케팅 시작일 기준 1년 이내 이탈자들의 복귀 확률을 산출하였습니다.
Data Preparation
데이터는 마케팅 시작일 기준 1년 동안의 데이터를 활용했으며 이용한 독립 변수 목록은 아래와 같습니다. 데이터는 zeppelin에서 pyspark문법과 SQL을 활용하여 불러왔습니다.
- 과금액, 과금 횟수 등의 과금 관련 변수 7종
- 접속 시간, 접속 횟수 등의 접속 관련 변수 11종
- 캐릭터 개수, max 캐릭터 레벨 등 캐릭터 관련 변수 6종
- 보스 몬스터 킬 수, 창고에 아이템 넣음 등의 인게임 변수 17종
종속 변수인 복귀/미복귀는 특정 날짜 기준 이탈했던 유저들을 대상으로 현재 서비스를 이용하고 있는 유저는 복귀, 그렇지 않고 아직까지 이탈 중인 유저를 미복귀로 지정하였습니다.
Data Preprocessing
Class Imbalancing
해당 산업에서 빈번하게 마주치는 문제 중 하나입니다. 보통 이탈 유저들의 복귀는 x% 수준으로 상당히 낮습니다. 서비스마다 다르지만 큰 차이는 보이지 않습니다. 이번 프로젝트에서 선정한 서비스는 다행히 상대적으로 높은 수준의 복귀율을 보이고 있지만 여전히 종속 변수에 대한 class 불균형 문제를 갖고 있었습니다.
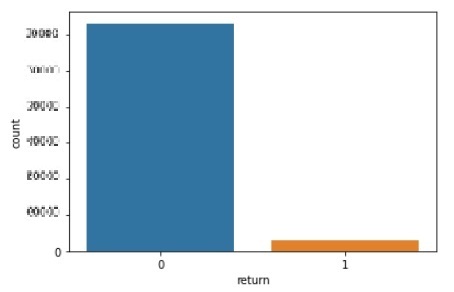
첫 번째로 접근한 방법은 random undersampling 이었습니다. 적은 label(복귀 유저 수)의 경우 데이터가 수만건이 되어 양은 충분하다고 생각했고 undersampling은 skewed dataset에서 더 효과적인 방법이라고 알려져 있기 때문에(A Dal Pozzolo, 2015) 첫 번째로 선택하였습니다. prototype으로 선택한 모델은 LGBM이었습니다.
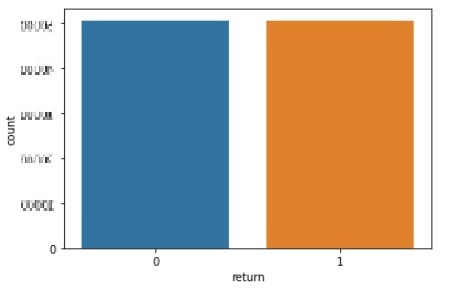
- After undersampling AUC : 0.512 -> 0.567
그 다음 적용한 rebalancing 방법은 SMOTE입니다. SMOTE는 현재는 모델링에서 가장 널리 알려져 있고 “잘 모르겠으면 Adam을 적용해라!” 하는 격언처럼 이용되고 있는 방법입니다.
- After SMOTE AUC: 0.567 -> 0.688
이 외에도 class imbalancing에 대처하기 위한 여러가지 방법이 있지만 해당 결과를 바탕으로 다음 단계로 진행하였습니다.
Correlation
모델을 크게 두 가지의 관점에서 만들었는데, 첫 번째는 모델에 대한 해석이 필요하지 않는 즉, 예측 확률값만이 필요한 경우와 두 번째는 복귀에 유의미한 영향을 미치는 요인이 무엇인지 해석이 필요한 경우입니다. 첫 번째 경우의 모델은 별다른 변수 선택을 거치지 않고 대부분의 독립 변수들을 이용하였습니다. 이는 추후에 MLops의 과정에서 전체 서비스와 상황별로 일반화하기 쉽다는 장점이 있습니다.
두 번째 경우는 상관 계수가 높은 변수들 중에서 서비스 차원에서 해석이 필요한 변수를 남기는 방식으로 진행하였습니다. 통계적 모델을 이용해서 검정 결과에 의존하는 방법도 있었지만, 해석이 필요한 경우는 보통 사업부와의 커뮤니케이션이 필요한 경우였기 때문에 p-value나 VIF, 신뢰구간에 의한 해석은 의사 소통을 더 어렵게 만든다고 생각하였습니다. 아래는 이번 프로젝트에서 진행한 독립 변수들 일부의 상관계수를 heatmap으로 표현한 것 입니다.
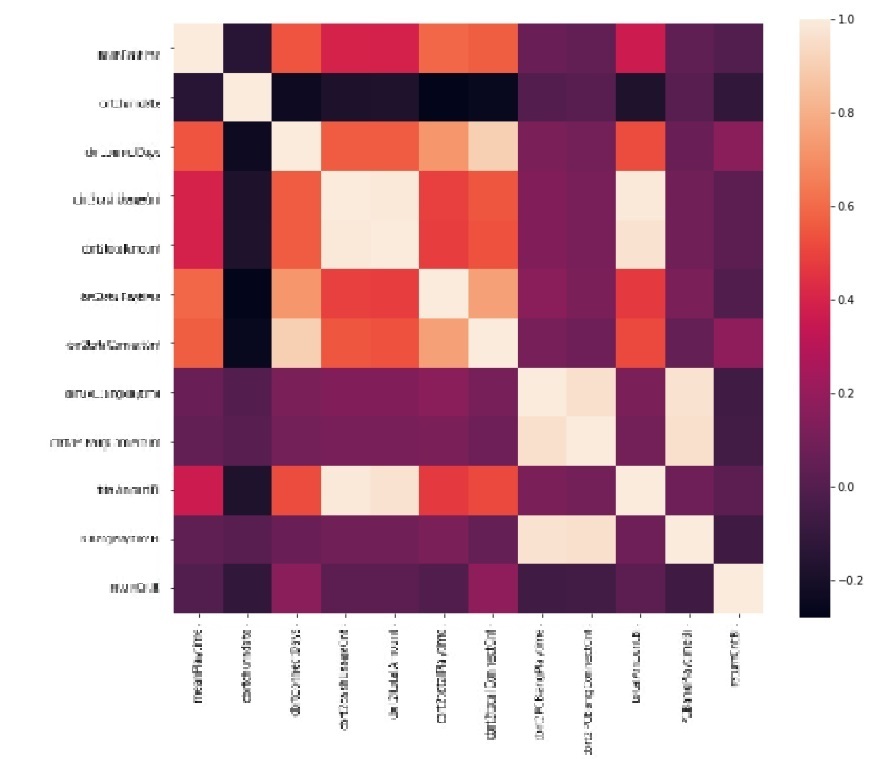
밝은색으로 표현된 부분은 변수간 상관계수가 높은 것을 의미합니다. 변수 제거의 조건을 상관 계수 0.5 ~ 0.7 다양한 기준으로 적용하여 확인하였으며 최종적으로는 0.7 이상인 변수들을 제거하기로 하였고, 서비스 차원에서 더 의미가 있는 변수를 선택하고 나머지를 제거하였습니다. 아래는 그 결과입니다.
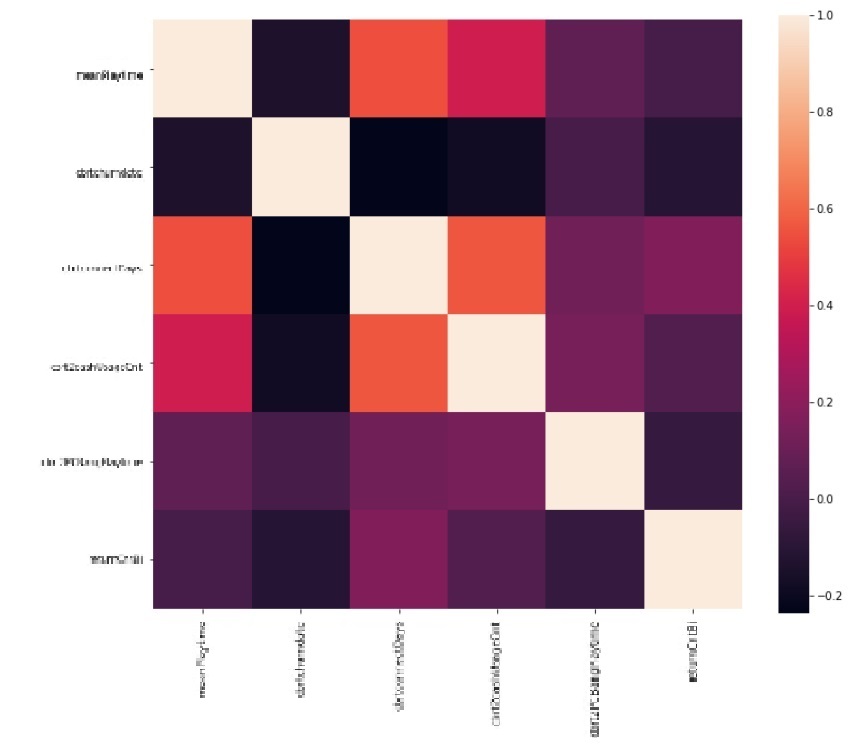
일반적으로 ML 모델은 종속 변수와 독립 변수와의 선형성을 가정하지 않으며, 이론적으로 multicollinearity의 문제는 이러한 선형성의 가정이 필요한 모델에서 나오기 때문에 어느정도 자유롭다고 알려져 있습니다. 하지만 (L Toloşi, 2011) 등에 따르면 여전히 상관계수가 높은 독립 변수들은 bias의 측면에서 모델 적합에 어려움을 준다는 연구 결과들이 있습니다. 실제로도 이번 프로젝트의 데이터에서도 높은 상관계수를 갖는 변수들을 삭제한 후 약간의 validation 성능 향상이 있었습니다.
- After Feature Selection AUC: 0.688 -> 0.693
Modeling
모델링은 크게 알고리즘의 선택과 선택한 알고리즘에 대한 hyper-parameter tuning으로 나뉜다고 생각합니다. 제가 속한 조직은 정확도 0.1점을 올리기 위해 리소스를 투자하기 보다는 적당한 성능의 모델을 만들고 이를 통해 실제 마케팅을 진행하고 인사이트를 얻는데 초점이 맞춰진 조직입니다. 따라서, 모델링에 큰 시간을 투자하지 않았고 알고리즘의 선택은 동료 데이터 사이언티스트 분들과의 협의를 통해 LightGBM으로 진행하였습니다. 사실 tuning에 대한 필요성도 많지 않았지만 LightGBM으로 모델이 hyper-parameter에 민감한 모델이기 때문에 이 부분은 간과할 수 없었습니다.
최적화에 대한 알고리즘은 Bayesian optimization을 이용하여 진행하였습니다. 최적화에 이용된 모수와 범위는 다음과 같습니다.
{
‘num_leaves’: (16, 512),
‘learning_rate’: (0.0001, 0.1),
‘n_estimators’: (16, 512),
‘subsample’: (0, 1),
‘colsample_bytree’: (0, 1),
‘reg_alpha’: (0, 10),
‘reg_lambda’: (0, 50),
}
optimization 진행은 다음과 같았습니다.
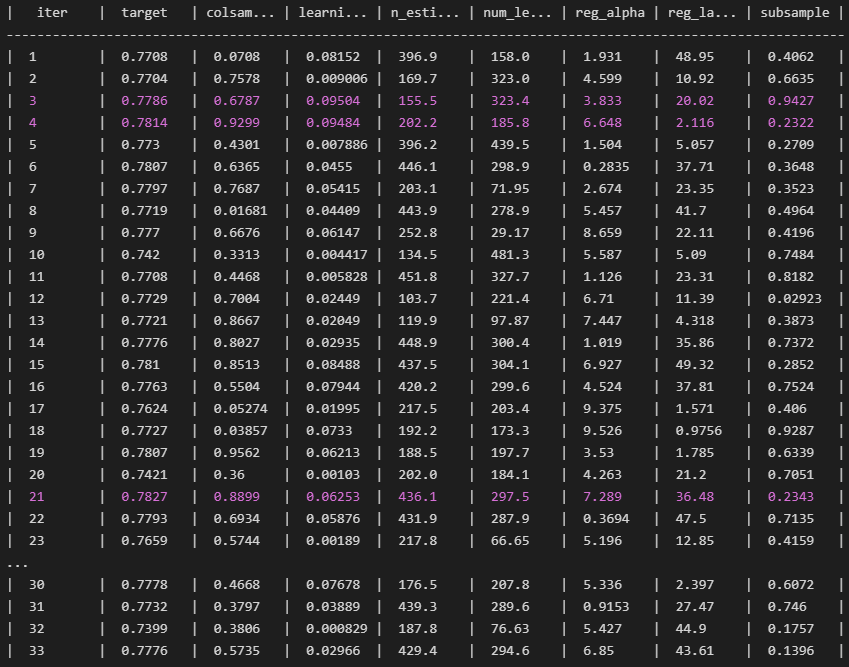
위의 결과는 훈련 데이터의 일부를 검증 데이터로 이용하여 튜닝을 진행한 결과입니다. 튜닝 후 기존에 validation 성능 측정에 이용하던 데이터에 대한 성능은 위 사진보다는 약간 낮은 결과가 나왔습니다. 이는 보통 validation score 보다 test score가 낮게 나오는 경향 정도의 수준이었습니다.
- After hyperparameter-tuning: 0.693 -> 0.738
더 많은, 더 넓은 범위의 hyperparameter를 이용하고 nested cross validation을 적용하는 등 약간의 성능 향상에 대한 가능성이 남아 있었지만, 이커머스 분야에서의 논문에서 주로 달성하던 복귀 확률 정확도가 0.7후반 ~ 0.8초반인 것을 감안했을 때 크게 나쁘지 않은 수준이었습니다. 해당 결과를 바탕으로 팀 차원에서 더 이상의 튜닝에 리소스를 투자하지 않기로 결정하였습니다.
Result
이렇게 만들어진 복귀 확률 모델을 활용하여 전체 이탈 유저에게 광고하는 것보다 더 효율적으로 광고를 집행할 수 있게 되었습니다. 당시 대규모 이벤트를 계획하고 있던 한 서비스와 함께 광고를 집행하기로 하였습니다.
당시 저희 팀에서는 전체 이탈 유저들에게 복귀 확률을 기반으로 군을 나누고 광고를 집행하여, 어떤 복귀 확률 구간의 유저 그룹이 광고에 긍정적인 반응을 하는 compliers들인지 알아보는 실험 광고를 계획하였습니다.하지만 서비스의 상황과 예산상 이는 불가능하고 compliers라고 예상되는 구간을 나누어 광고를 집행하였습니다. 아래는 그 결과입니다.

우선, 서비스 이탈 9일 ~ 180일인 유저들을 모두 추출한 후 각각의 유저들에 대한 복귀 확률을 예측하였습니다. 그 후 상위 7.5% ~ 30%의 유저들을 4개의 군으로 나눈 뒤, 각 군을 다시 타겟군과 대조군으로 분리하였습니다.
결과를 살펴보면 복귀 확률이 높은 유저 그룹일수록 실제로 높은 복귀율을 보이고 있는 것을 확인할 수 있었습니다. 이는 곧 모델이 정상적으로 작동한다는 것을 알 수 있습니다.
또한, 해당 결과에서 compliers 그룹은 가장 마지막인 1571 그룹인 것을 알 수 있습니다. 타겟군과 대조군의 복귀율 차는 곧 광고의 효과로 해석될 수 있고 유의수준 0.05 수준에서 통계적으로 유의한 광고 효과를 보이는 군은 1571군 이었습니다.
한가지 아쉬운 점은 복귀 확률 상위 30% 미만인 그룹에서 더 큰 광고 효과를 볼 수도 있지만 이는 실제로 확인하지 못했다는 점 이었습니다. 그리고 추후 여러 다양한 서비스, 다양한 환경에서도 복귀 확률을 근거로한 comliers들을 찾는 것이 실험 과제로 남아있습니다.
해당 프로젝트 결과를 바탕으로 현재 저희 팀은 “복귀 확률을 통한 효율적인 광고 집행”이라는 타 팀이나, 외부 광고 업체가 따라할 수 없는 하나의 옵션을 갖게 되었으며 현재까지도 각 서비스에서 많이 이용되고 있습니다.